[Preface: I got Windows 10 Pro to detect dual monitors with a AMD ATI Radeon HD 4250 graphic card, which AMD and most other people will say you can’t do.]
Apologies to librarians reading the blog, as I’ve been in a much more technical place lately, but maybe you’ll find the following useful too.
Recently, I’ve been putting together a computer (with a AMD Phenom(tm) II X6 1055T processor) at work, which my boss is going to send home with me, so that I can work remotely from home.
It already had Windows 8.1 running fine on it, but we decided to upgrade to Windows 10 just to be as up-to-date as possible. We packed up the drive with Windows 8.1, cloned Windows 10 onto another drive, plugged it into the machine, turned it on, and wished for the best.
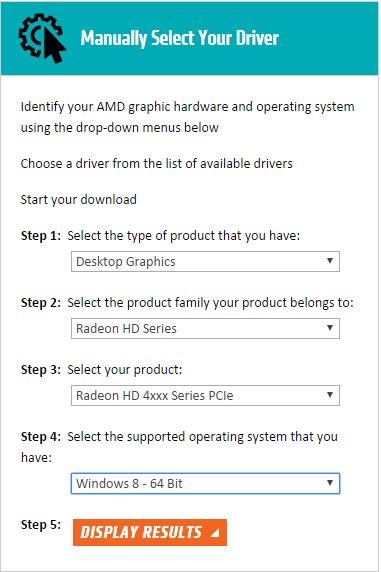
Everything seemed to come up fine, but the display was being duplicated rather than extended across 2 monitors. After booting into Windows 10, the computer also said that it was missing AMD graphical drivers. I’d encountered a similar problem in the past, so I hopped onto AMD’s website (http://support.amd.com/en-us/download), and noticed that they didn’t have any up-to-date drivers for Windows 10 for their ATI Radeon HD 4xxx series. The last Windows operating system I found supported was Windows 8. See the below image for what criteria I used on the AMD website.
The more I read online, the more dire it seemed to be. Most people said that you were up the creek without a paddle… some people gave suggestions which didn’t work… and at the end of it all… I figured I’d have a crack at it myself.
I downloaded the AMD driver auto-detect tool, and it said it couldn’t find any drivers for my system. I’d seen such things before and figured I’d discount this as the auto-detect isn’t great.
I downloaded the Radeon HD 4xxx Series PCIe drivers I could find (as you can see in the image above), which claimed to work with Windows Vista, Windows 7, and Windows 8. They came bundled up in an installer (13-1-legacy_vista_win7_win8_64_dd_ccc.exe), so I downloaded the whole thing, and tried installing that and restarting
No luck.
I tried uninstalling the AMD Catalyst Control Center (ie the “ccc” from the .exe installer), restarting, re-installing, restarting… no luck.
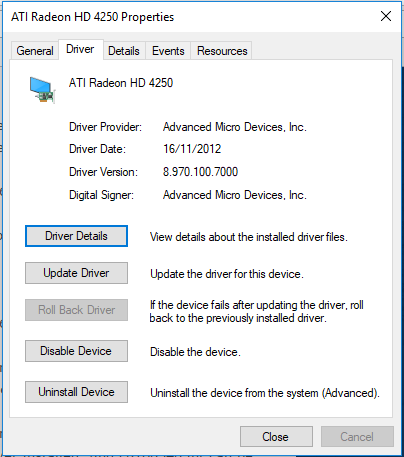
I pressed “Win + R” to get a Run prompt, typed in “devmgmt.msc” to get the device manager up. I expanded the “Display adapters” which listed the AMD ATI Radeon HD 4250 device, right-clicked and clicked on Properties, and went to the “Driver” tab.
There I clicked “Update Driver…”, “Browse my computer for driver software”, “Let me pick from a list of device drivers on my computer”, chose “Microsoft Basic Display Adapter”, and clicked “Next”. I restarted the computer, and… it still wasn’t detecting my second monitor.
So I tried uninstalling the AMD Catalyst Control Center again, restarting, reinstalling… and this time I got an extra pop-up during the process. It claimed to be from”Advanced Micro Devices” (ie AMD) and related to the display, so I clicked install, and went back to my existing workstation… when out of the corner of my eye I saw the two monitors flicker. I focused on them and noticed that they were now extended and not duplicated!
I rushed over to the computer and found that AMD Catalyst Control Center didn’t appear to install correctly, but the computer now recognized the second monitor!
I often say that technology isn’t magic, but it seemed like magic!
So I went back to “devmgmt.msc”, went back to the properties for the Display adapter, and clicked on the “Events” tab. It displayed a history of driver installations for the day, and I noticed in the morning that it had installed “c0296217.inf” about 4 times. Then it added “Driver Service added (BasicDisplay)” and “Device installed display.inf”, which would’ve been the “Microsoft Basic Display Adapter”. Then… the final few entries said “Driver service added amdkmdag”, “Driver service added amdkmdag”, “Driver service added (AMD External Events Utility)”, “Device installed (c8160540.inf)”.
It wasn’t magic after all. Rather, the installer had used a different driver the final time! I searched C:\AMD for “c8160540.inf” and sure enough I found it at C:\AMD\Support\13-1-legacy_vista_win7_win8_64_dd_ccc\Packages\Drivers\Display\W86A_INF\C8160540.
I tried searching for “c0296217.inf” but I couldn’t find it in the C:\AMD directory. My guess… is that when I was trying to install the AMD Catalyst Control Center… it must’ve been using drivers that were already existing on the system. Even though the drivers didn’t work… it tried the pre-existing bad ones before it used the good new one that it had packaged with itself. Now that’s 100% a guess, but it’s clear that the final driver that works was one that I had downloaded with the 13.1 installer.
I wish I knew more about the overall process, but in the end I got my desired result, and that’s what matters most at the moment. Hurray for getting Windows 10 Pro to work on that machine with dual monitors! Also… hurray for being able to use remote desktop connection with dual monitors!
Now to pack up the hardware and get it home, and… spend the next 3 hours doing everything that I was originally going to do in 7.5 hours today.
Little victories…
Edit (22/05/2018):
Every Windows Update uninstalls the working AMD drive with either a generic driver or a newer AMD driver which doesn’t work. Here’s a little reminder to myself (and others) that this is the particular Driver Date and Driver Version which works with the ATI Radeon HD 4250 (at least on this computer).